Learning Zero-Shot Multifaceted Visually Grounded Word Embeddingsvia Multi-Task Training
Abstract
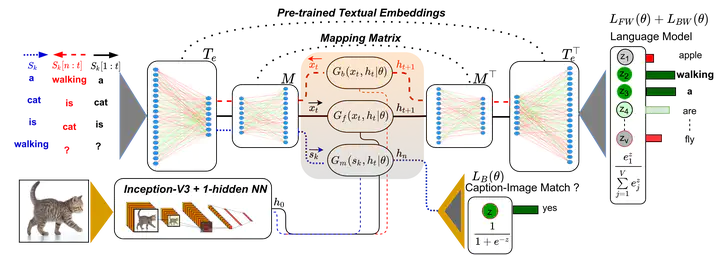
Language grounding aims at linking the symbolic representation of language (e.g., words) into the rich perceptual knowledge of the outside world. The general approach is to embed both textual and visual information into a common space -the grounded space- confined by an explicit relationship. We argue that since concrete and abstract words are processed differently in the brain, such approaches sacrifice the abstract knowledge obtained from textual statistics in the process of acquiring perceptual information. The focus of this paper is to solve this issue by implicitly grounding the word embeddings. Rather than learning two mappings into a joint space, our approach integrates modalities by implicit alignment. This is achieved by learning a reversible mapping between the textual and the grounded space by means of multi-task training. Intrinsic and extrinsic evaluations show that our way of visual grounding is highly beneficial for both abstract and concrete words. Our embeddings are correlated with human judgments and outperform previous works using pretrained word embeddings on a wide range of benchmarks.
Hassan Shahmohammadi
Senior Research Scientist
My research interests include Multi-Modal learning, NLP, Generative Models